So organisieren Sie Ihren geteilten Posteingang mit KI
Eine praxisnahe Anleitung, die zeigt, wie sich Tausende unstrukturierter E-Mails in eine Datenkarte mit hierarchischen Themen verwandeln lassen.

Warum die meisten Teams das Signal übersehen
Jeden Tag verarbeiten Organisationen riesige Mengen unstrukturierten Texts: E-Mails von Kunden, Helpdesk-Tickets, interne Dokumente, Chat-Protokolle, Feedback-Formulare, Richtlinienhinweise und vieles mehr. Es ist nicht allein die Menge, sondern auch die Vielfalt und das Rauschen, die diese Daten so schwer beherrschbar machen.
Teams organisieren unstrukturierte Daten mit Tags, Buckets, Spaces und Ähnlichem. Trotzdem erhalten sie damit noch immer keinen hochaufgelösten Blick darauf, was diese Woche stark ansteigt, welche Themen wachsen und was zuerst behoben werden sollte.
Warum entgeht den meisten Teams das Wesentliche? Die Realität ist: Statische Kategorien und verstreute Dashboards verdecken das Signal. Was Führungskräfte wirklich brauchen, ist ein lebendiges Bild davon, welche Probleme gerade wachsen, was sie antreibt und wie man konsistent darauf reagiert.
Beispiele für Buckets, in die Kundenanfragen eingeordnet werden, sind Abrechnung & Zahlungen, technischer Support, Serviceausfälle usw. Diese Buckets sind grob und hinken der tatsächlichen Kundenstimmung oft hinterher. Teams sehen in der Regel nur Zählwerte nach statischen Kategorien, es fehlt der tiefere Einblick in Muster auf Cluster-Ebene oder in Veränderungen einzelner Themen über die Zeit. Ohne fortgeschrittene Textanalyse fällt es Unternehmen schwer, Stärken und Verbesserungsfelder zu erkennen und datengestützte Entscheidungen aus ihren Kundenfeedback-Daten abzuleiten.
Die Chance liegt offen vor uns: Jedes Kundensupport-Team besitzt bereits eine Goldmine, nämlich Tausende vergangener Tickets und die Antworten, die sie gelöst haben. In Cluster und Themen strukturiert, verschafft dieses „Unternehmensgedächtnis“ Operations-Teams und dem Management endlich einen Echtzeit-Blick auf ihren Betrieb im großen Maßstab. Ebenso wichtig: Es bildet die Grundlage für LLM-basierte Agenten, wie wir sie bei Interloom entwickeln, die neue Anliegen wirksamer bearbeiten können.
In diesem Beitrag zeigen wir eine kurze Anleitung anhand eines öffentlichen Datensatzes, erklären den Ansatz in einfachen Worten und teilen die Kennzahlen, die belegen, dass er funktioniert.
Ein schneller Praxisdurchlauf (mit einem öffentlichen Datensatz)
In der heutigen Realität bearbeiten die meisten Support-Teams Tickets reaktiv. Ein menschlicher Mitarbeiter erhält die Nachricht eines Kunden, versucht, spontan die beste Antwort zu formulieren, und macht weiter. Das Problem? Es gibt keine einfache Möglichkeit zu wissen, ob ein Kollege genau dasselbe Anliegen vor zwanzig Minuten bereits gelöst hat, oder ob es sich um eine neue Art von Problem handelt, das dokumentiert und geteilt werden sollte. Wertvolles Wissen verschwindet in einzelnen Postfächern und Chat-Verläufen.
Um das Chaos zu verringern, führen Unternehmen oft manuelle Kategorien ein (z. B. „technischer Support“, „Produktsupport“), um Tickets zumindest zu zählen und weiterzuleiten. So hilfreich das ist, dieser Ansatz hat gravierende Grenzen: Kategorien sind statisch und zu grob, sie erfassen selten die eigentlichen Ursachen oder aufkommenden Muster, und Teams verbringen weiterhin Zeit damit, Antworten neu zu erfinden, statt Wissen wiederzuverwenden.
Das Ergebnis ist ein Arbeitsablauf, der sich wie Brandbekämpfung anfühlt: Jedes Problem wird ad hoc gelöst, ohne den Vorteil eines kollektiven Gedächtnisses oder eines Überblicks darüber, was wirklich geschieht.
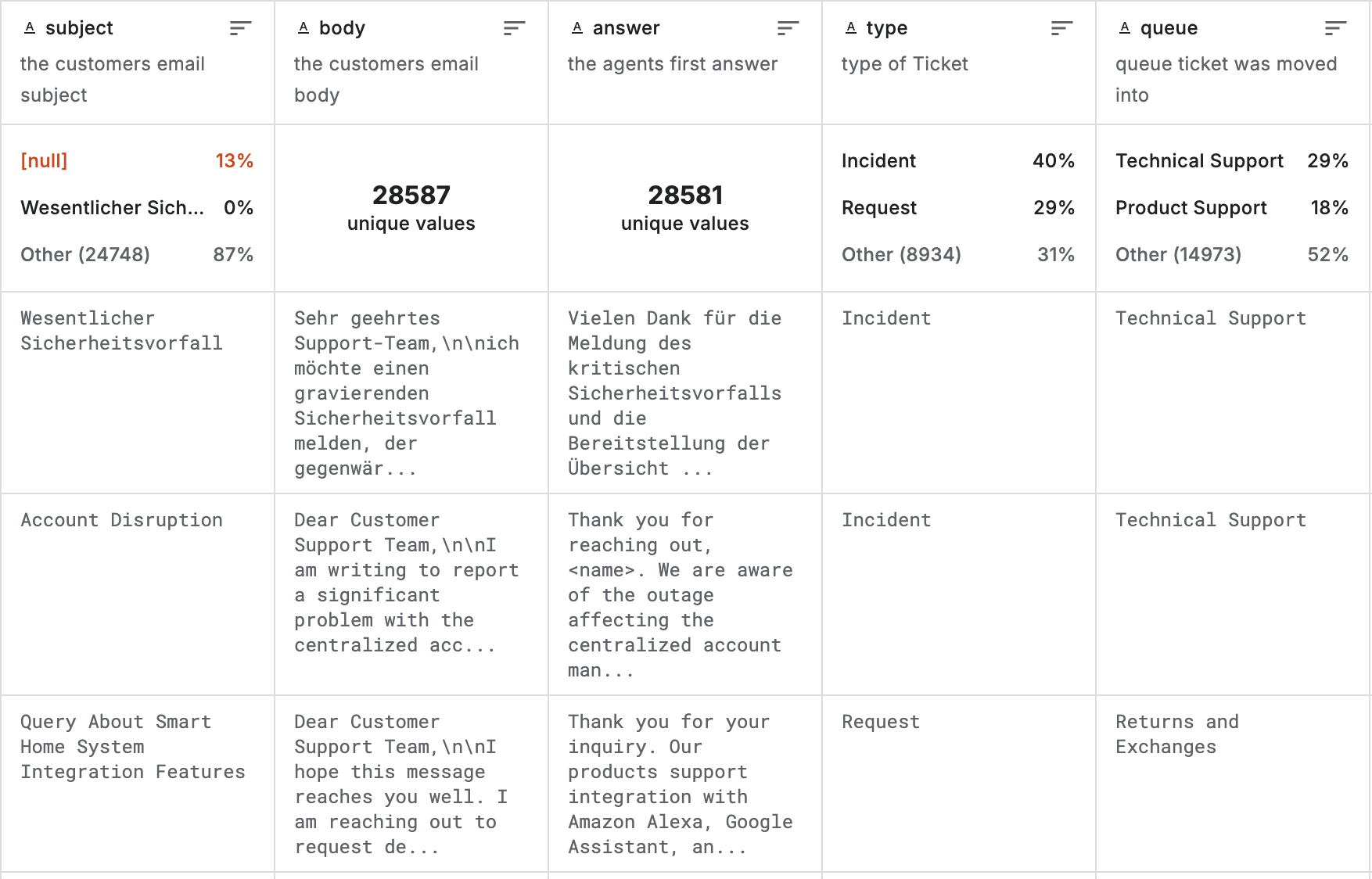
Sehen wir uns ein praktisches Beispiel mit einem Customer IT Support - Ticket Dataset an. Der Datensatz enthält rund 30.000 echte Kundensupport-Vorgänge, wobei jeder Eintrag eine E-Mail eines Kunden samt der ersten Antwort des Unternehmens erfasst.
Verwandeln wir ihn in eine handlungsleitende Ansicht und analysieren zunächst die übergeordneten Probleme.
Kritische Problem-Cluster identifizieren
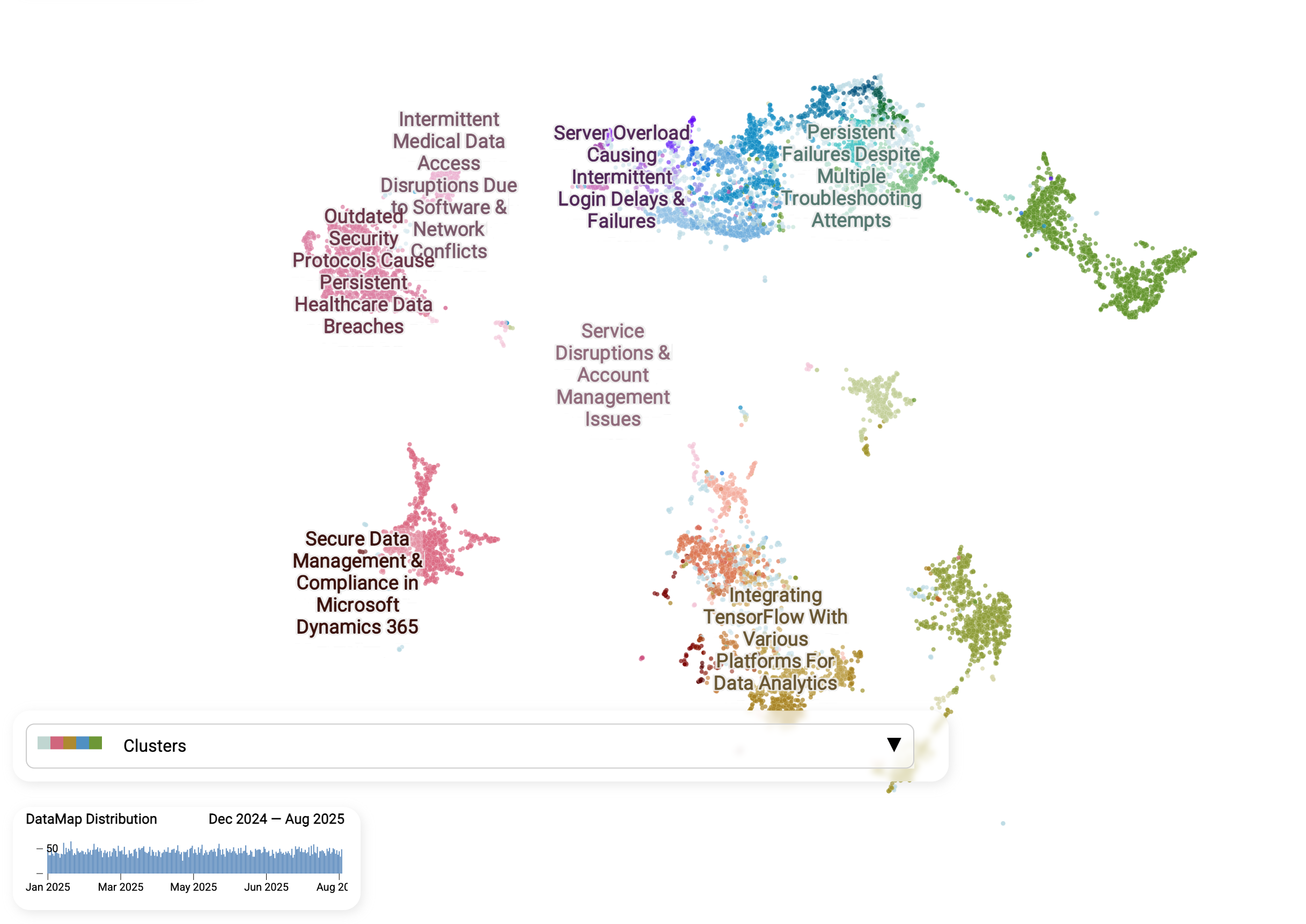
Diese Karte ist eine visuelle Momentaufnahme des Datensatzes, wobei jeder Punkt eine einzelne Konversation zwischen einem Kunden und dem Support-Team darstellt. Das ist kein herkömmliches Streudiagramm und kein Balkendiagramm, bei dem die Kategorien vorab festgelegt sind. Stattdessen entdeckt die KI Kategorien automatisch, indem sie jedes Ticket liest, ihre Bedeutung vergleicht und ähnliche Anliegen einander „finden“ lässt.
- Nahe beieinanderliegende Punkte bedeuten ähnliche Anliegen. Indem jede Nachricht in einen „Bedeutungsvektor“ überführt wird, erkennt die KI, wenn verschiedene Kunden dieselbe Art von Problem beschreiben, selbst wenn sie unterschiedliche Worte oder Sprachen verwenden.
- Cluster entstehen von selbst. Anders als statische Ticket-Kategorien („technischer Support“, „Produktsupport“) sind diese Gruppen nicht vordefiniert. Sie bilden sich anhand der tatsächlichen Sprache der Kunden, sodass Muster zum Vorschein kommen, die sonst verborgen blieben. Man sieht, wie sich Tickets zu eigenständigen Inseln gruppieren, etwa „Serverüberlastung führt zu Login-Verzögerungen“, „anhaltende Ausfälle trotz Fehlerbehebung“ oder „sichere Datenverwaltung in Microsoft Dynamics 365.“ Das sind Anliegen, die in einem herkömmlichen System unter statischen Sammelkategorien untergehen würden.
- KI-generierte Labels. Die KI benennt jedes Cluster automatisch, sodass Teams schnell erkennen, worin die eigentlichen Probleme bestehen, statt sich durch Ticket-IDs zu wühlen.
- Trends sind nachverfolgbar. Die Zeitleiste am unteren Rand zeigt, wann Anliegen sprunghaft ansteigen, sodass Teams aufkommende Probleme früh erkennen und handeln können, bevor sie eskalieren.
KI verwandelt einen verrauschten Posteingang in eine geordnete Problemkarte, auf der Teams von groben Themen bis zu präzisen Teilproblemen hineinzoomen können und Agenten diese Erkenntnisse für schnellere, konsistentere Antworten nutzen.
Ein Cluster näher betrachtet: Serverüberlastung → zeitweise Login-Fehler
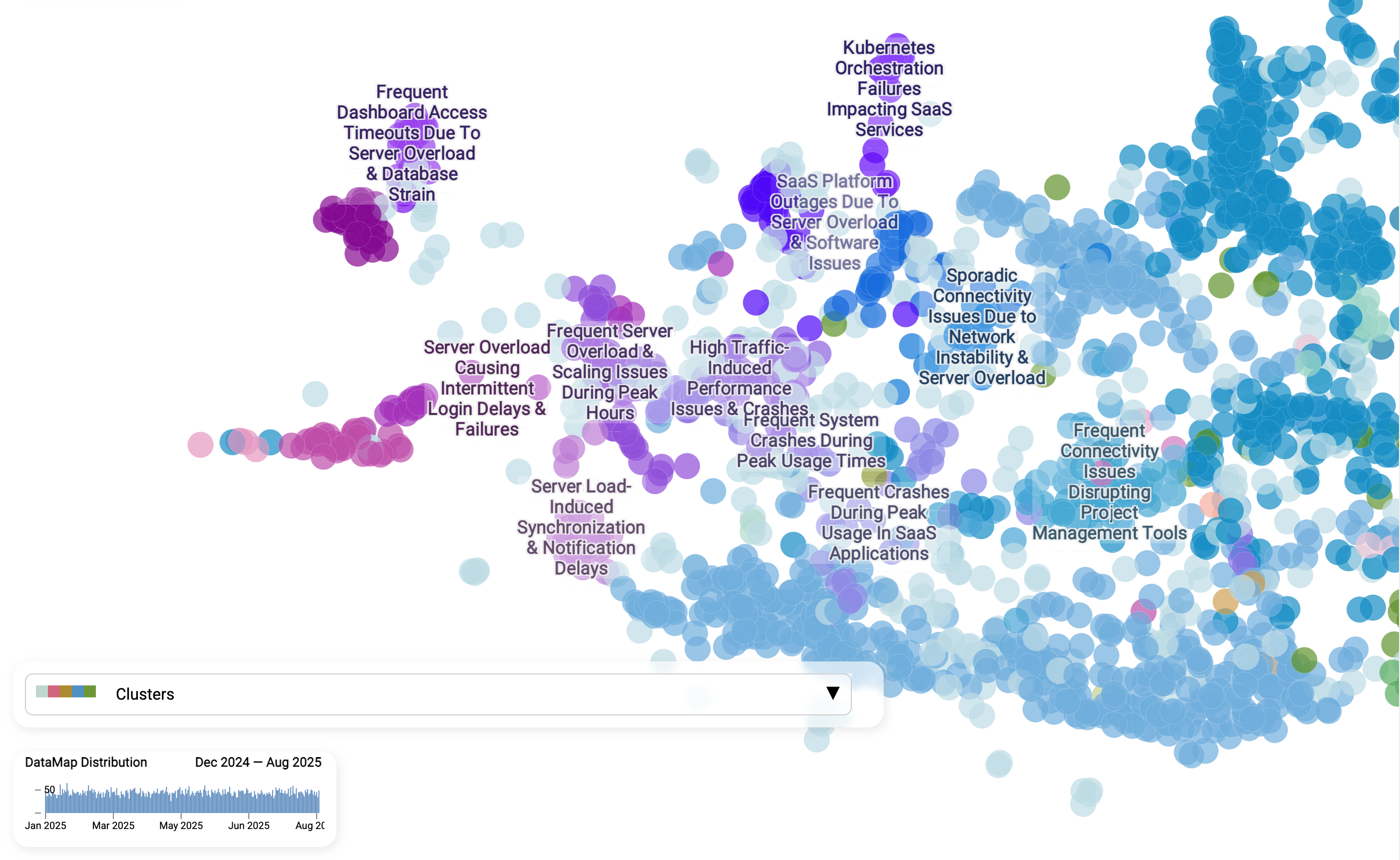
Hier zoomen wir in ein bestimmtes Cluster: „Serverüberlastung → zeitweise Login-Fehler.“ Jeder Punkt ist weiterhin ein einzelnes Ticket. Kunden beschreiben Login-Probleme auf unterschiedliche Weise, doch die KI erkennt die gemeinsame Bedeutung. Sub-Cluster zeigen Nuancen. Innerhalb des übergeordneten Themas erkennt das Modell feinere Schattierungen des Problems:
- Serverüberlastung zu Spitzenzeiten
- Skalierungsprobleme, die zu langsamen Logins führen
- Benachrichtigungs- und Synchronisationsverzögerungen infolge der Last
- häufige Abstürze bei Traffic-Spitzen
Warum das wichtig ist. Statt „Login-Probleme“ nur als einen vagen Bucket zu sehen, erhalten Teams eine strukturierte Aufschlüsselung der verschiedenen Ursachen. Das erleichtert es, Verantwortlichkeiten zuzuweisen (z. B. Infrastruktur vs. Software), Korrekturen zu priorisieren und präzisere Antworten zu verfassen.
Diese Zoom-Ansicht zeigt, dass die KI Tickets nicht bloß zu generischen Haufen gruppiert, sondern sie in eine lebendige Hierarchie ordnet: breite Themen oben, spezifische Fehlerbilder darunter. Das ist der hochaufgelöste Blick, den statische Kategorien niemals bieten können.
Sind „Login-Fehler“ ein neues oder ein fortlaufendes Problem?
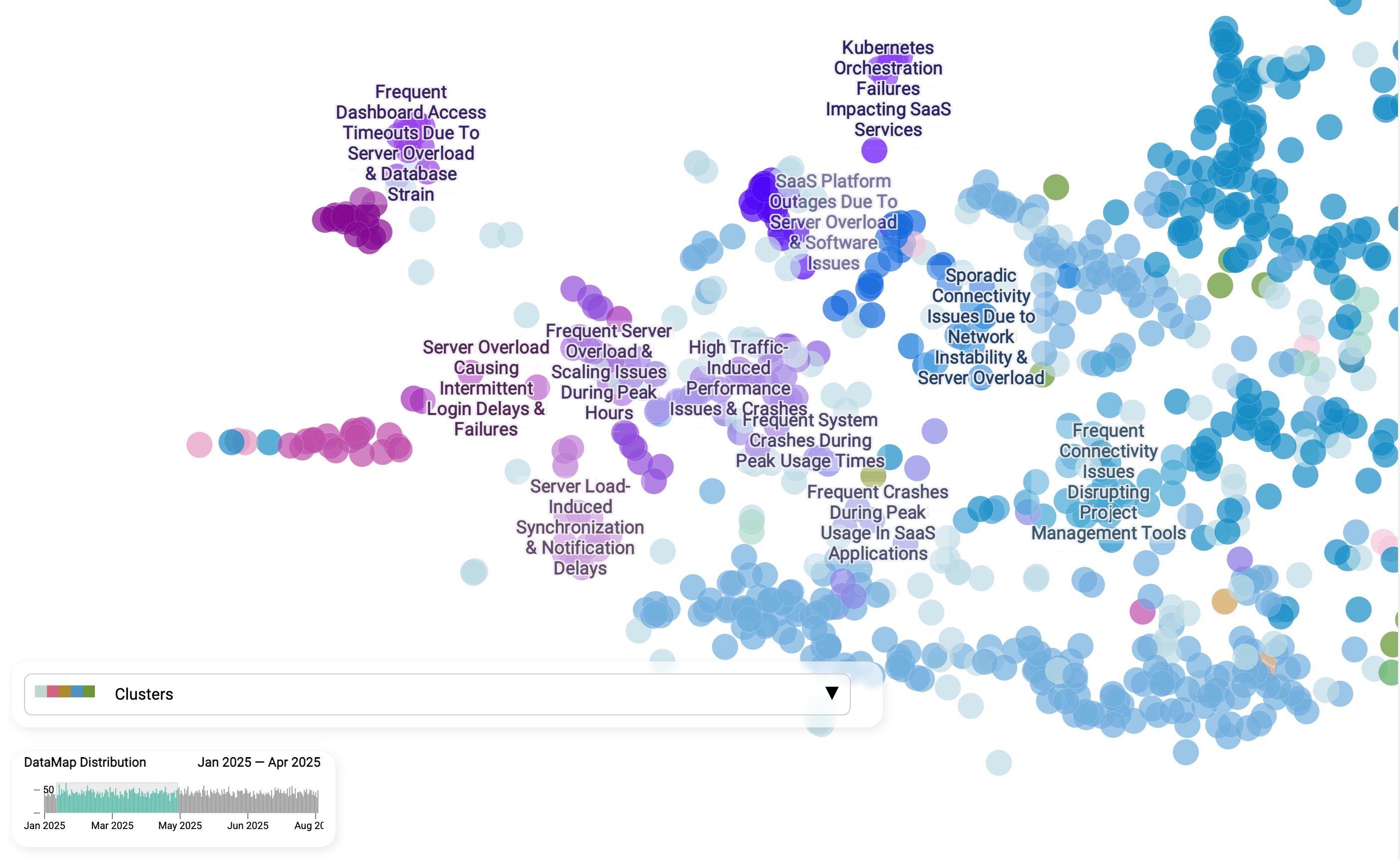
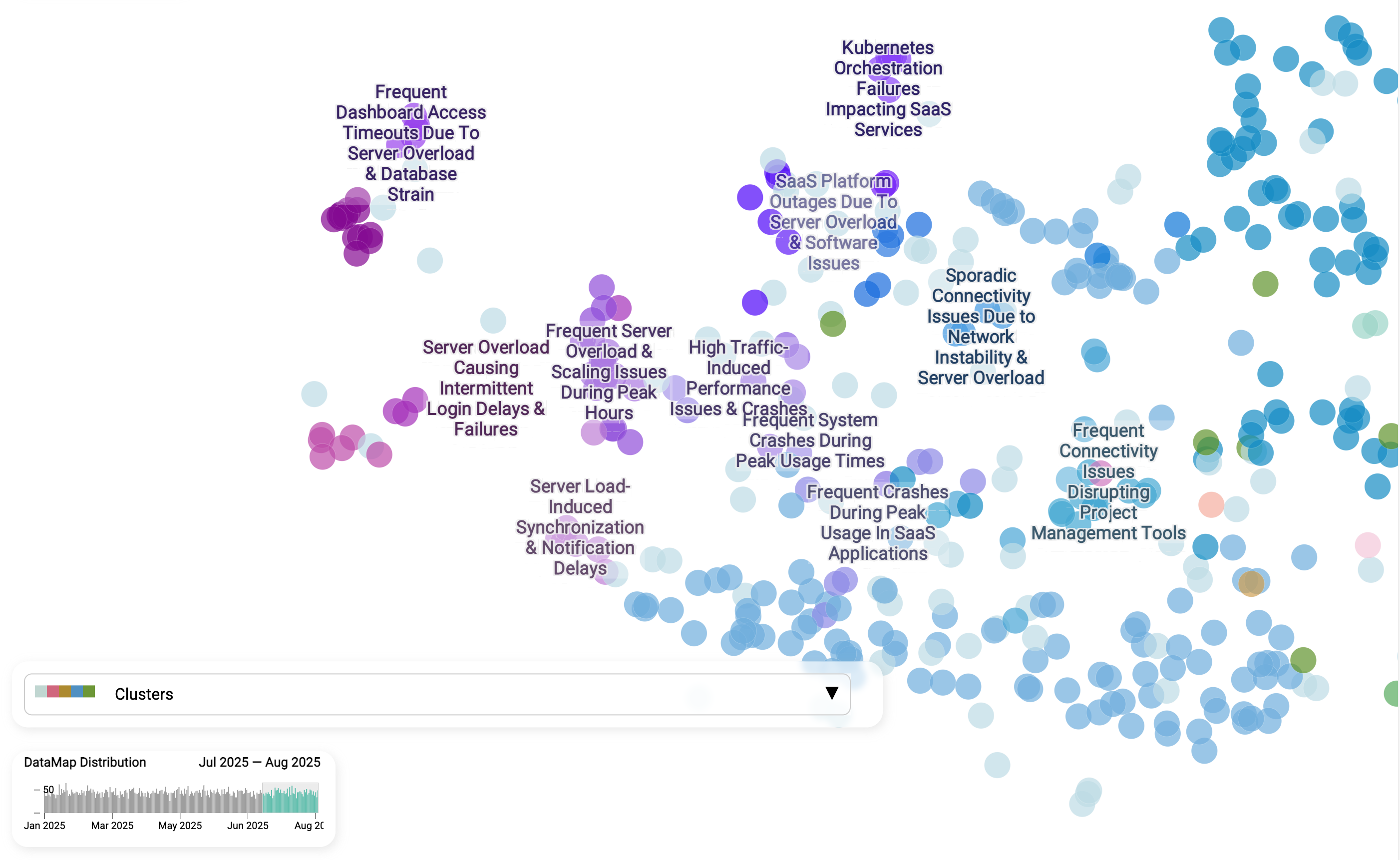
Stellen wir uns folgende Geschichte vor, die in jeder Organisation passieren könnte: An einem Freitag, nach dem Release der Authentifizierungskonfiguration, erhält ein Teammitglied mehrere E-Mails von Kunden, die Probleme melden. Das Team ist verunsichert, denn es hatte bei den neuen Änderungen keine Probleme erwartet. Wie bekommen wir mehr Klarheit darüber, ob es nur Zufall ist oder die neuen Änderungen tatsächlich die Login-Probleme verursacht haben?
Eine Datenkarte, die reale Fälle in Echtzeit aggregiert, würde diese Information in Sekunden offenlegen. Wenn wir das Cluster Login-Fehler von Januar bis April mit Juli bis August 2025 vergleichen, wird die Geschichte klar: Das ist kein einmaliger Aussetzer, sondern ein anhaltendes, ungelöstes Problem. Dieselben Unterthemen, Serverüberlastung, Skalierungsprobleme zu Spitzenzeiten und Synchronisationsverzögerungen, treten in beiden Zeiträumen durchgängig auf. Eine solche Ansicht ist deshalb so wirkungsvoll, weil sie chronische Schwachstellen von neuen Vorfällen trennt. Statt zu raten, ob ein Anstieg an Support-Tickets mit einem aktuellen Release zusammenhängt oder eine langjährige Schwäche darstellt, können Teams Muster über die Zeit erkennen, Verantwortlichkeiten zuweisen und in strukturelle Lösungen investieren, statt endlos Brände zu löschen.
Kunden in ihren eigenen Worten hören
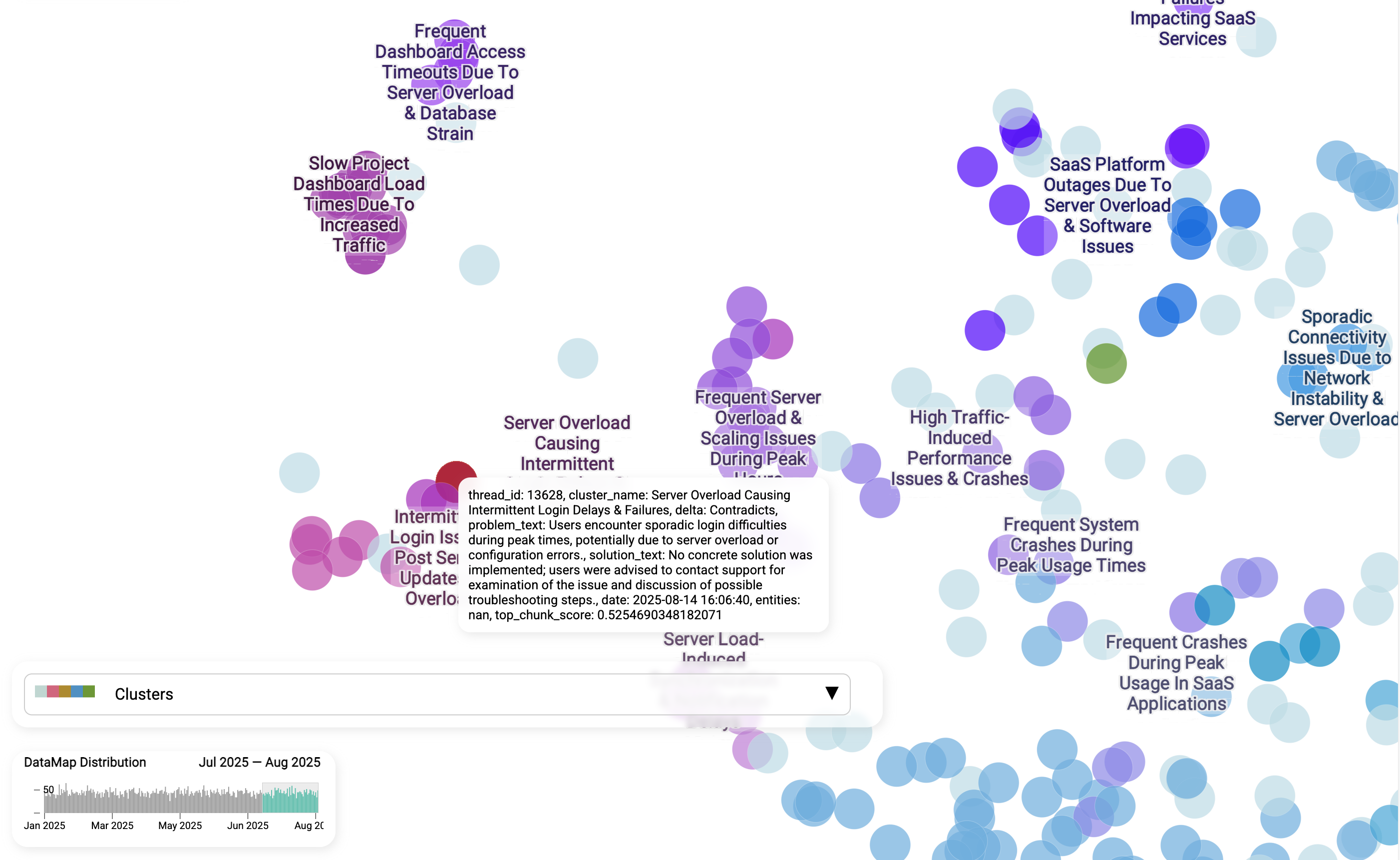
Über die Cluster und Labels hinaus können wir auch in einzelne Tickets hineinzoomen, um Kunden in ihren eigenen Worten zu hören. Jeder Ausschnitt zeigt, wie Menschen das Problem tatsächlich beschreiben: „sporadische Login-Schwierigkeiten zu Spitzenzeiten“, „langsames Laden des Projekt-Dashboards“ oder „es wurde keine konkrete Lösung umgesetzt.“
Das ist wichtig, weil es Teams eine Perspektive von der Basis verschafft, die Zahlen allein nicht bieten können. Führungskräfte sehen die echte Kundenerfahrung, während Support-Agenten dieselbe Formulierung und denselben Kontext in ihren Antworten aufgreifen können. Das lässt Antworten nicht nur empathischer und relevanter wirken, sondern hilft auch sicherzustellen, dass Lösungen daran ausgerichtet sind, wie Nutzer ihre Probleme tatsächlich in Worte fassen.
So funktioniert es
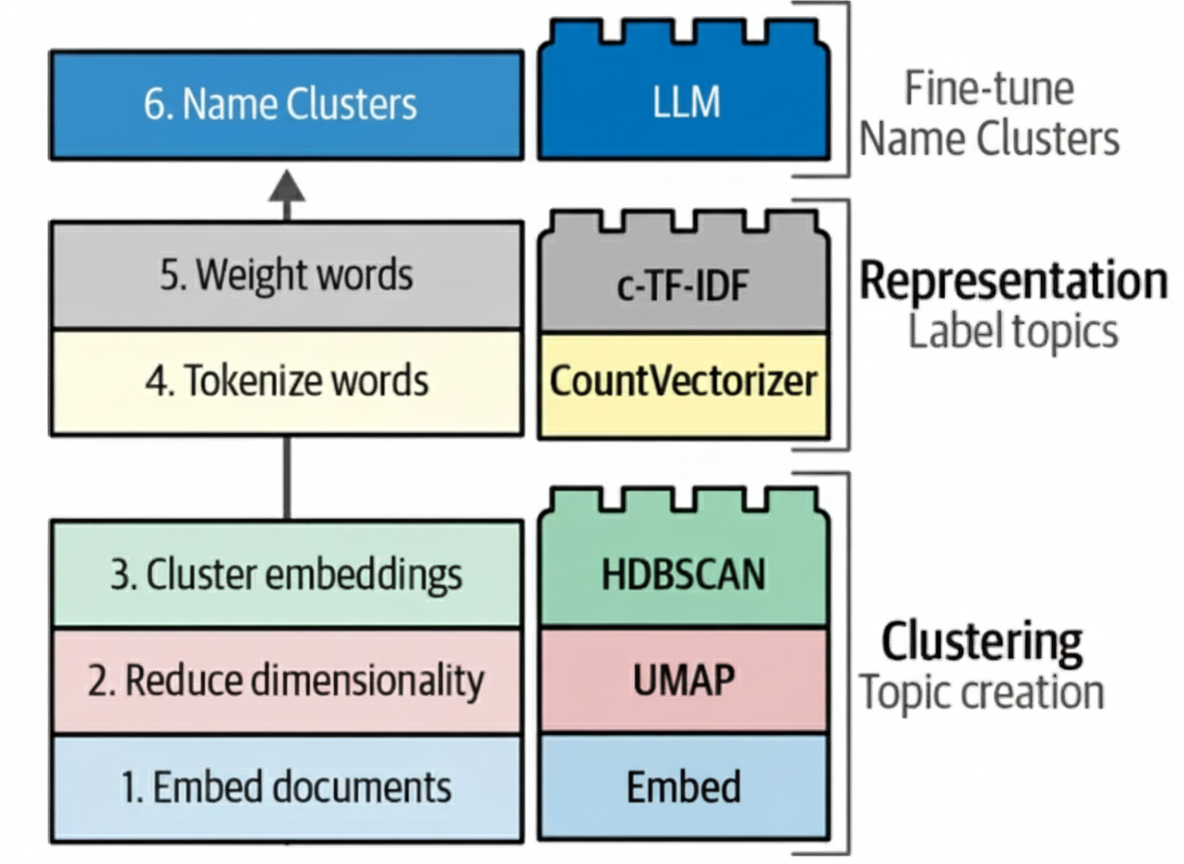
Schritt 1 - Chaotische Konversationen in saubere Datensätze verwandeln.
Wir setzen einen KI-Assistenten ein, der jeden Ticket-Verlauf liest und vier Felder erfasst: Problem, Lösung, Lösungsschritte und Entitäten (z. B. Produkt, Version, Region). Der Assistent überprüft sich selbst und versucht es erneut, wenn er unsicher ist.
Schritt 2 - Ähnliche Anliegen gruppieren.
Jedes Problem wird in einen numerischen „Bedeutungsvektor“ überführt (ein Embedding). Ähnliche Tickets liegen nahe beieinander, sodass wir Cluster bilden können, von breiten Themen bis hin zu spezifischen Teilproblemen. Dazu nutzen wir semantische Embeddings & Ähnlichkeitssuche, hierarchisches Clustering sowie Themenmodellierung & Labeling.
Schritt 3 - Benennen, überwachen und handeln.
Wir versehen Cluster mit kurzen, menschenlesbaren Labels, bauen Dashboards, um Spitzen und Trends zu erkennen, und verknüpfen jedes Cluster mit einer einheitlichen Antwort und einem Verantwortlichen. Damit schließt sich der Kreis von der Erkenntnis zur Handlung. Anwendungsfälle für LLM-gestützte Agenten: LLM-Agenten, die neue Tickets bearbeiten, erhalten Cluster-Kontext und repräsentative Lösungsdatensätze, um in Echtzeit besser zu antworten, zu triagieren oder zu eskalieren, indem sie ihre Antworten in vorhandenem Wissen verankern und Halluzinationen reduzieren.
Von der Erkenntnis zur Handlung: LLM-basierte Agenten schließen den Kreis
Ihr Team besitzt die Goldmine bereits: vergangene Tickets und bewährte Antworten. In Cluster und Themen geordnet, wird dieses „Unternehmensgedächtnis“ zur Grundlage für LLM-basierte Agenten, die neue Anliegen wirksamer bearbeiten können.
- Verankerung in echter Historie. Statt Antworten zu erfinden, können Agenten auf repräsentative frühere Fälle zurückgreifen, formuliert so, wie Kunden tatsächlich sprechen, und gelöst so, wie Experten sie tatsächlich gelöst haben. Das senkt das Halluzinationsrisiko und hält Antworten im Einklang mit den Unternehmensrichtlinien.
- Kontextbewusste Triage. Indem sie aufkommende Cluster sichtbar machen, können LLM-Agenten ihre Antworten auf den Moment zuschneiden und das heute brennende Thema (z. B. Login-Fehler, Abrechnungsänderungen) mit mehr Empathie und Präzision erklären.
- Hierarchisches Schlussfolgern. Frameworks wie Chain-of-Agents oder Data Interpreter bilden die geschichtete Struktur von Support-Problemen ganz natürlich ab, breite Kategorien oben, spezifische Grundursachen darunter, und lassen Agenten so zusammenarbeiten wie menschliche Teams.
- Intelligentes Context-Engineering. Bei begrenzten Kontextfenstern passt nicht jede Ticket-Historie hinein. Aggregierte Cluster-Ansichten ermöglichen es Agenten, nur die relevantesten Beispiele und komprimierte Zusammenfassungen auszuwählen und so die Genauigkeit zu maximieren und zugleich die Kosten zu kontrollieren.
In der Praxis bedeutet das: LLM-Agenten beginnen nicht bei null. Sie stehen auf den Schultern Tausender früherer Lösungen und verwandeln vergangene Erfahrung in schnellere Antworten, weniger Eskalationen und klügere Entscheidungen, und schließen so den Kreis vom chaotischen Posteingang zur automatisierten Lösung.
Zusammenfassung
Indem sie chaotische Posteingänge in strukturierte Datensätze, Cluster und klare Visualisierungen verwandeln, gewinnen Support-Teams einen hochaufgelösten Blick auf die Schmerzpunkte ihrer Kunden. Sie sehen, was im Trend liegt, führen Anliegen auf ihre Grundursachen zurück und koordinieren einheitliche Antworten. In Kombination mit LLM-basierten Assistenten schließen diese Erkenntnisse den Kreis und liefern schnellere Antworten, weniger Eskalationen und einen gesünderen Backlog.